

You cannot AI your way out of a data problem - Why agentic security requires a security-domain-aware data foundation
TL;DR
- Agentic security fails without a security-domain-aware data foundation, not because data is raw, but because today's pipelines were designed for human search, not machine reasoning.
- Three layers power every autonomous detection loop: Signal Memory (90-day behavioral baseline), Intent Graph (behavioral purpose across entities), and an Action Layer governed by policy, remove any one and the loop breaks.
- Production infrastructure now runs on AI agents. Unlike human identities, they operate continuously, access systems at machine scale, and drift from their established behavioral baseline in ways no static detection rule was written to surface.
- The real differentiation is not the model. It is the security domain expertise encoded into TASC: the Trench Agentic Semantic Context. The accumulated decisions about what to extract, normalize, resolve, and enrich that no generic pipeline makes for you.
CONTEXT
In Clearing the Clutter, we established why AISOC failed - messy data, static detection, no architectural foundation. In Headless SecOps, we showed what the right foundation enables: Zero UI, Conversational UX, and On-Demand Context. This post goes under the hood, the three architectural layers that make it real.
Every vendor in security operations is now shipping an AI agent. Most of them are wrapping it around an architecture designed for a different consumer: a human analyst, reading a screen, at human speed. The demos land. The production deployments, three months later, are quietly disappointing. The data layer those agents reason over was not built for them either. TASC is Trench's answer to that gap.
There is a second, faster-moving problem on top of this. The more consequential shift is not in corporate productivity tools, it is in production infrastructure itself. API orchestration layers spawning sub-agents mid-request. Data pipelines with autonomous write access to core systems. Model-driven decision engines embedded directly into business critical workflows and risk scoring. These systems run continuously, carry the highest-privilege access in the environment, and generate behavioral patterns no human analyst has ever needed to characterize because until recently, they did not exist.
This creates an entirely new class of detection challenge.
- What does “normal” look like for an AI agent processing 10 million events a day?
- What constitutes anomalous access for an orchestration layer designed to call arbitrary downstream APIs? The threat models, the baselines, the behavioral signatures, none of them exist yet.
- Human threat experts are encountering attack patterns in agentic infrastructure that have no historical precedent. That deserves a dedicated post, and we will cover it.
For now: the only foundation capable of characterizing new baselines at this speed is one designed for continuous behavioral reasoning not static rules written against behaviors we already understood. The organizations that get the foundation right now will defend both: their own detection agents, and the production infrastructure those agents are embedded in.
The real problem isn’t “raw data”
To be fair to the existing approach: modern SIEMs are not doing nothing. Splunk does index-time extraction for default fields. Elastic has full pipeline processing. Panther, Anvilogic, and Cribl do real security-aware normalization. The industry has been moving in the right direction on data processing for years.
The problem is that normalization has been optimized for a human analyst’s workflow. An agent has fundamentally different requirements.
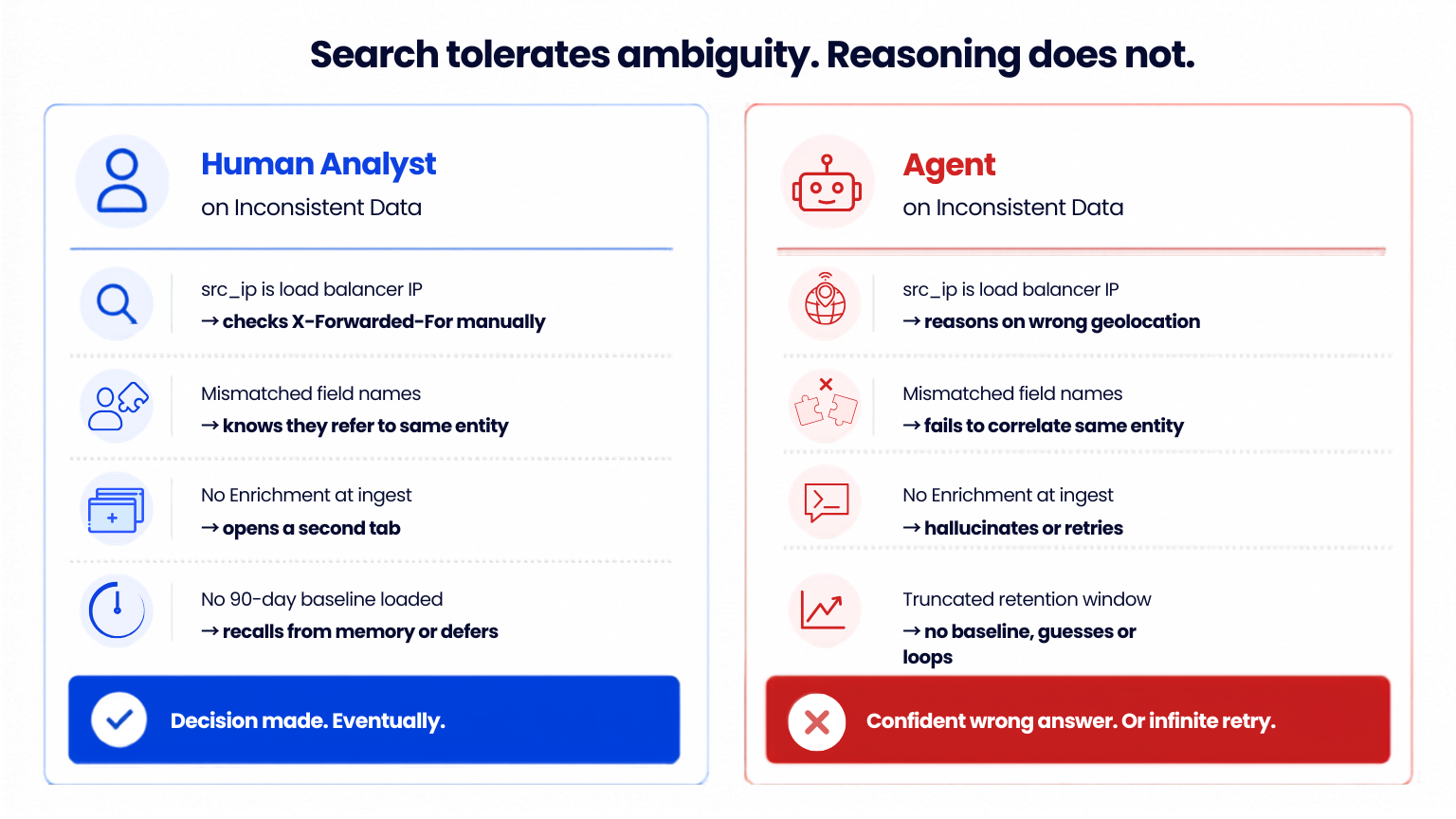
Fig 1: Search tolerates ambiguity. Reasoning does not. The same data inconsistency is a recoverable nuisance for a human and an operational failure for an agent.
Search tolerates ambiguity. Reasoning does not. A human analyst who finds an inconsistent field compensates with domain knowledge. An agent that finds an inconsistent field hallucinates, retries, or produces a confident wrong answer. At the scale and speed agents operate, the second failure mode is operationally dangerous.
Three layers. Remove any one and the loop breaks.
Every autonomous detection-and-action loop requires three architectural layers in sequence. This is where the security-first data foundation makes the Agentic Threat Detection Mesh operationally real, the infrastructure layer of what we call the Agentic Operating System for Actionable SecOps.
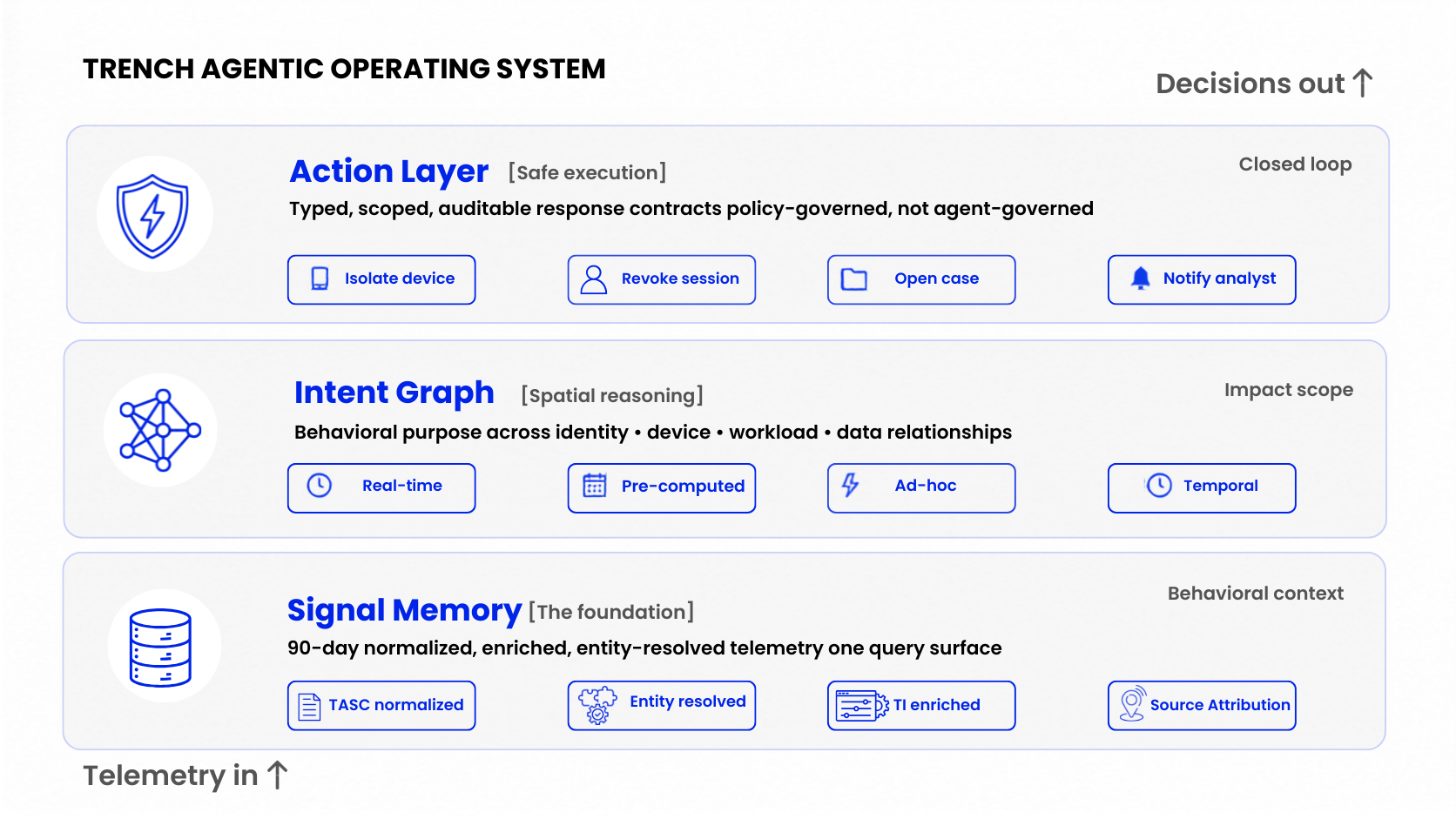
Fig 2 - The Trench Agentic Operating System: Signal Memory (base), Intent Graph (middle), Action Layer (top). Data flows up; decisions flow down. Remove any layer and the loop breaks.
Layer 1 - Signal Memory
Consider three service accounts in a FinTech payout environment. Each has a clean 90-day behavioral baseline. In the final three weeks of that window, each begins to drift independently, along separate paths, toward the same sensitive resource. The first, svc-payouts-api, begins calling the payout configuration endpoint: 2 calls, then 5, then 11. The second, svc-identity-sync, quietly begins accessing the same endpoint from a different trust path. The third, api-integration-03, acquires read access to the downstream core banking write interface.
No single entity crosses a threshold. A rate-of-change rule on any one of them fires nothing. Rules describe shapes; they don't detect convergence across entities. Signal Memory surfaces the per-entity drift for each but only because 90 days of behavioral history makes the deviation visible. What that drift means requires the next layer. That history is only queryable because TASC (Trench Agentic Semantic Context) normalizes every event to a consistent, meaning-aware structure at the point of ingestion.
Signal Memory Query: behavioral drift, 90 days, one call [Illustrative Shape]
-- Behavioral drift: what a detection rule cannot catch
-- No single event trips a threshold. The pattern only emerges over 90 days.
SELECT
api_endpoint,
COUNT(*) AS weekly_calls,
DATE_TRUNC('week', event_time) AS week_start,
DENSE_RANK() OVER (
ORDER BY DATE_TRUNC('week', event_time)
) AS week_num -- 1 through ~13
FROM signal_memory
WHERE entity_id = 'svc-payouts-api'
AND event_time >= NOW() - INTERVAL '90 days'
GROUP BY api_endpoint, week_start
ORDER BY week_start, api_endpoint;
-- Run for each of the three entities independently:
-- svc-payouts-api: 'payout_config_write' appears weeks 11-13
-- svc-identity-sync: 'payout_config_write' appears weeks 12-13
-- api-integration-03: 'core_banking_read' appears week 13
-- No threshold broken on any single entity.
-- The convergence is only visible across all three.Signal Memory is no longer merely storage. It is a single query surface across the full retention horizon. The same capability that detects a drifting human identity also detects a drifting agent identity operating in your production systems.
Layer 2 - The Intent Graph
Three entities. Three independent drift signals. Each invisible to a rule written against any one of them. The Intent Graph is what makes the convergence visible because it does not ask "has this entity changed?" It asks "what is the combined shape of everything that is moving toward this resource right now?"
This is the question no rule can answer. A Sigma rule operates on a single event stream. An SPL query operates on one entity at a time. Neither holds the behavioral history of three separate entities and their relationships to a shared downstream resource simultaneously. The Intent Graph does because it encodes not just what is connected, but the behavioral purpose behind each relationship across the entire environment.
The Intent Graph is only coherent because TASC (Trench Agentic Semantic Context) resolves entities and encodes relationships at ingest before the graph is built, not after.
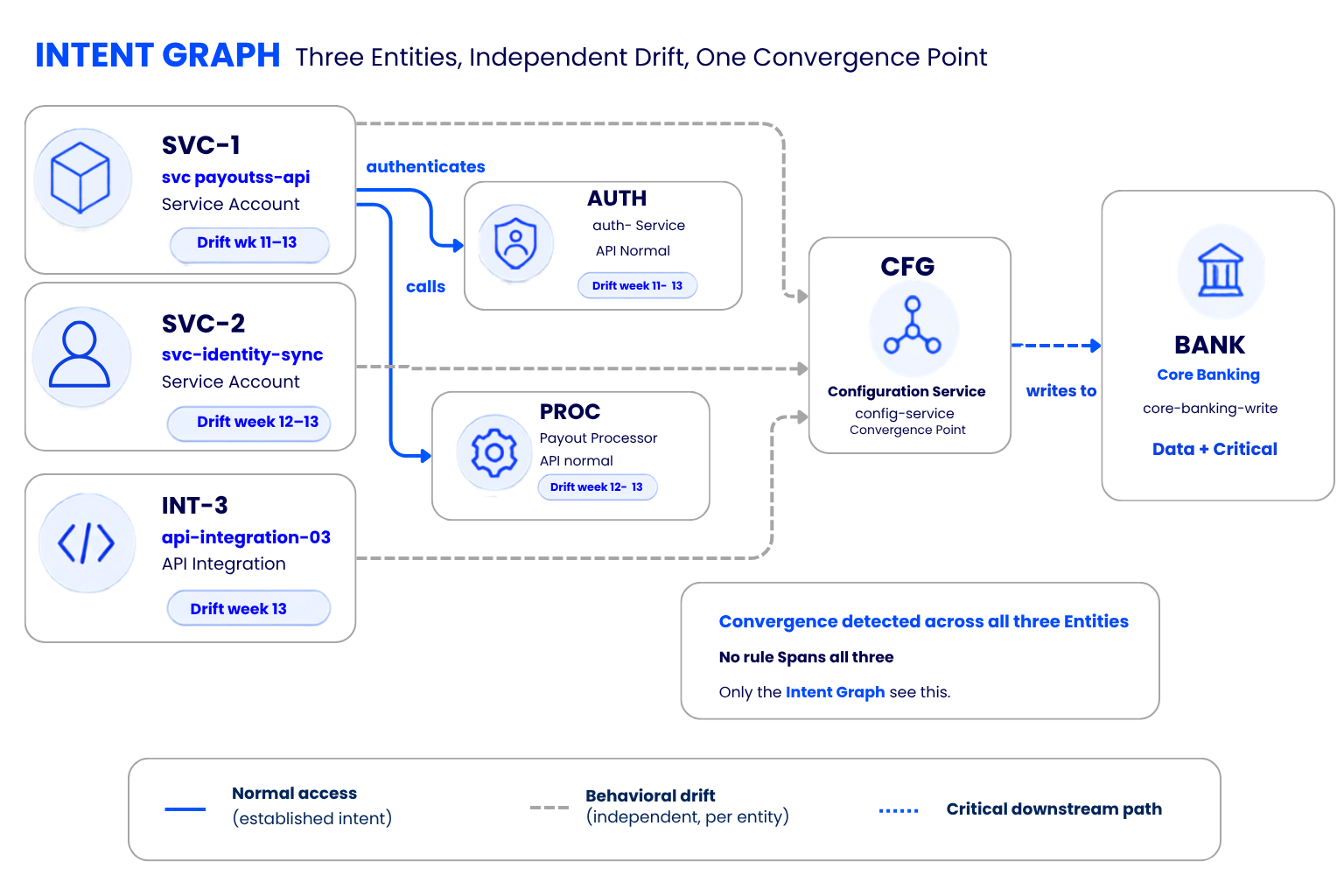
Fig 3 - Intent Graph: three entities drifting independently toward the same sensitive resource. No single entity crossed a threshold. No rule spans all three paths. The convergence is only visible at the graph level which is precisely where TASC-normalized data makes it queryable.
Four access patterns, one graph:
- Real-time - live mirror of all assets and relationships, answers ‘what is reachable right now’ with no ETL lag
- Pre-computed - materialized views of expensive traversals: reachability, privilege chains, critical-asset neighborhoods. One compute, thousands of reads
- Ad-hoc - dynamic multi-hop queries composed mid-investigation, budget-aware so one exploration query can’t starve the live path
- Temporal - time-indexed edges that let the agent reconstruct the environment as it stood at any point in the baseline window. This is the access pattern incident responders actually need and almost never have: when an investigation starts today, the attacker may have moved three weeks ago. Point-in-time detection sees the present state of the environment. Temporal graph traversal reconstructs the attack surface as the attacker first saw it, the privilege paths that existed then, the access that has since been quietly removed. That is the difference between finding the entry point and missing it entirely.
Every serious platform will have some form of graph. But graphs have shapes. A graph built from cloud asset configurations answers “what is exposed.” The Intent Graph, built from security telemetry, sign-ins, device posture, workload access, and behavioral history, answers “if I act on this, where breaks and where did the attacker already reach?” Those are different graphs.
It is the spatial reasoning layer that determines whether an agent’s decision is grounded in the full context of the environment - or just the last event it saw.
Layer 3 - The Action Layer: the trust problem that gets too little attention
Clean Signal Memory and a good Intent Graph get an agent to the right decision. They don’t make that decision safe to act on automatically.
A false positive in a query wastes an investigation. A false positive in a containment action takes down a production service at 2 A.M. At a FinTech payout platform, isolating the wrong service account mid-batch-run is not an inconvenience, it is a service incident.
Action contract - what the agent sees
{
"name": "security.respond.isolate_device",
"description": "Network-isolate a device, preserving forensic state.",
"scopes": ["respond.isolate"],
"side_effects": "high",
"requires_approval": "policy" // customer sets this, not the agent
}The key field is requires_approval set by the customer, not by us, not by the agent. Configure isolating workstations automatically while requiring approval before revoking a service account credential. The scope is yours to set and yours to expand.
Three questions decide whether a CISO trusts autonomous action. What is the audit trail? Every action the agent takes, proposed, approved, executed, or overridden, is logged with a timestamp, the reasoning that produced it, and the identity that approved it. Nothing is invisible. What is the rollback story? Containment actions in Trench are time-bounded by design. An isolated device is automatically released at the duration limit unless explicitly extended. A revoked session can be reinstated in one click from the same Slack thread that closed it. What happens when the agent is wrong? It will be wrong. The architecture assumes this. Every autonomous close feeds back into TASC as a signal, the engineer who overrides a decision does not just fix the incident, they correct the model. The system gets more accurate in the specific environment it is operating in, not in a generic training set.
Trust expands as accuracy is measured in production. That is the only honest way to earn autonomy at this layer.
What “security-domain-aware” actually means at the pipeline
Introducing TASC: Trench Agent Semantic Context
The data layer that existing schemas were not built to provide. TASC is OCSF-compatible in wire format but adds proprietary semantic enrichment OCSF doesn't specify. Where OCSF standardizes format, TASC standardizes meaning: the layer that turns raw telemetry into agent-ready context; it is a proprietary schema designed independently for agent reasoning. Organizations who want portability should know: TASC is the Trench-specific layer;the normalized output it produces can be queried through standard interfaces, but the semantic enrichment is ours.
TASC normalization: same event, three sources, one schema
-- Before normalization: three sources, three schemas
-- Okta: actor.displayName + client.ipAddress
-- CrowdStrike: UserName + RemoteIP
-- Windows: SubjectUserName + IpAddress
-- After TASC normalization at ingest (Trench):
{
"class_uid": 3002,
"actor": {
"user": { "uid": "alice@company.com", "name": "Alice Chen" }
},
"src_endpoint": { "ip": "203.0.113.42" },
"enrichments": {
"threat_intel_score": 0.87,
"geo_anomaly": true
}
}
-- src_endpoint.ip is the true client IP, resolved through CDN/proxy headers.
-- enrichments applied at ingest, not at query time.
-- The agent doesn't know Okta from CrowdStrike. It knows Alice.| What | Standard | Why it matters for agents |
|---|---|---|
| TASC normalization | Schema standard | One query works across Okta, CrowdStrike, and Windows, the agent doesn’t know which schema it’s reading |
| True client IP resolution | Source-specific parsing | A FinTech stack behind a CDN frequently logs the proxy IP. Get it wrong and all geolocation-based detection fails silently |
| Entity resolution at ingest | Identity fabric | "alice@company.com", "alice", "CORP\alice", same person, three schemas. Resolving at ingest is what makes the Intent Graph coherent |
| TI enrichment at ingest | Pre-enriched records | Reputation scores applied at arrival. No separate API call mid-investigation, no stale enrichment on a live alert |
This is not a generic ETL provides out of the box. It requires security domain expertise baked into pipeline logic, decisions about what to extract, normalize, resolve, and enrich, made by people who understand why detection fails in practice. That is the core innovation layer of Actionable SecOps. Not the model. The accumulated decisions.
The loop end to end
This is the concrete expression of Headless SecOps in Conversational UX mode, a high-confidence threat requiring a judgment call, routed to Slack with full context pre-assembled.

Fig 4: Trench Detection-to-Action Loop. Steps ②-③ draw on Signal Memory and the Intent Graph. Step ⑤ surfaces the full context in Slack for one-click approval. Step ⑥ executes all three actions and closes the audit trail.
This loop exists in production. It works because every layer underneath it - normalized data, resolved entities, pre-enriched telemetry, the Intent Graph, scoped action contracts, was built to support it. Take out Signal Memory and step ② doesn’t run. Take out the Intent Graph and step ③ is guesswork. Take out the Action Layer and step ⑤ is a Slack message with no buttons and no audit trail.
Across our customer environments, we process millions of events daily. Our target is not maximum autonomous closure, it is high-confidence closure. Every alert the agent closes autonomously meets a confidence threshold set by the customer. Everything below that threshold surfaces to the engineer. The result: security engineers spend their time on the cases that genuinely need judgment, not on confirming what the agent already knows.
Why the timing matters now
Frontier AI models now release on months-long cycles, not years. Each new generation brings sharper reasoning, broader tool use, and a faster ability to discover and exploit vulnerabilities including ones that no detection rule has ever described, because the attack pattern has never existed before. The blindspots are not shrinking. They are proliferating faster than any static detection library can keep up with. The only practical response is a foundation that lets agents reason over behavior, not just match patterns. That foundation is TASC and it needs to be in place before the agents arrive, not retrofitted after.
Every AI agent your organization deploys in production is a new principal in your environment with real permissions, real access, and behavior patterns that drift gradually from established baselines in ways threshold-based rules cannot surface. Securing those agents requires the same foundation that powers Trench’s detection agents: 90-day behavioral baselines per entity, a graph that encodes intent not just topology, and action contracts that a human can audit and calibrate.
You cannot AI your way out of a data problem. The organizations that treat data quality as a prerequisite to AI adoption will see the difference in production. The gap between them and the ones who defer it is not staying constant, it is compounding. Every month of clean, enriched, entity-resolved telemetry is a month of behavioral baseline the agent can reason over.
Want to go deeper?
- AI in Security Operations: Clearing the Clutter - why AISOC failed and the two foundational problems that must be solved
- Introducing Headless SecOps for the Agentic World - Zero UI, Conversational UX, and On-Demand Context in practice


